Overview
Built IAN, an institutional assistant for INSA Toulouse that answers student questions by combining semantic search (FAISS + MiniLM) with a large generator (Mixtral‑8x7B) using a RAG pipeline. The system prioritizes up‑to‑date factual answers and clear failure messages.
Data Collection
We implemented a Java scraper targeting INSA public pages and Moodle:
- 6,215 pages harvested in ~20 minutes
- ≈4.45M words extracted, 55% of documents with identifiable update date
- Limitations: scanned PDFs, images and complex tables required manual handling
Experimental Roadmap
We compared three approaches:
- From‑scratch small language models (PyTorch) — computationally expensive, poor results without large infrastructure
- Fine‑tuning GPT‑2 on local data — modest gains; human evaluation: ~3.8% fully satisfactory responses
- RAG (final solution) — retrieval + generation gave best practical results and supports live updates
RAG Pipeline
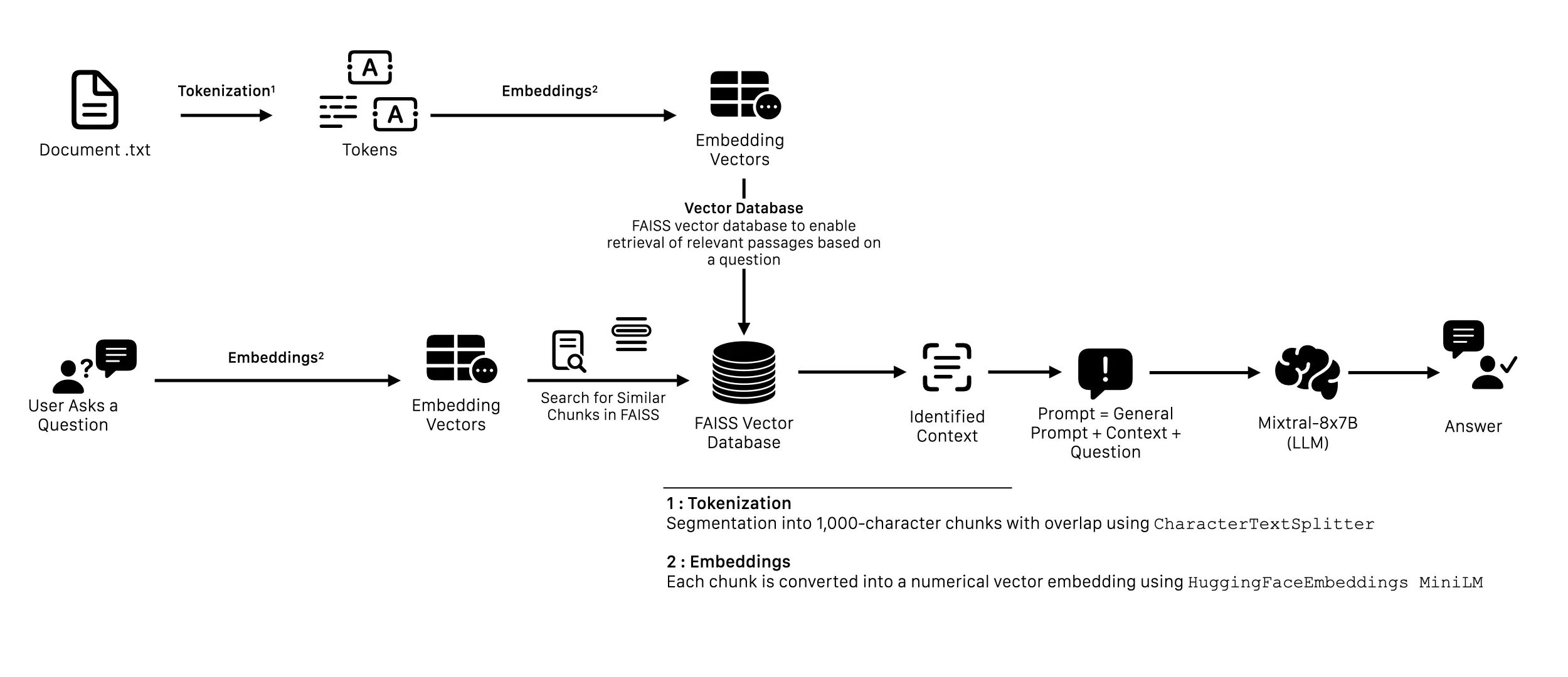
Pipeline summary:
- Chunk documents into 1000‑char segments
- Embed with MiniLM, index vectors in FAISS
- At query time, retrieve top segments and pass them to Mixtral‑8x7B alongside the prompt
Benefits: up‑to‑date answers without heavy re‑training.
Evaluation & Tools
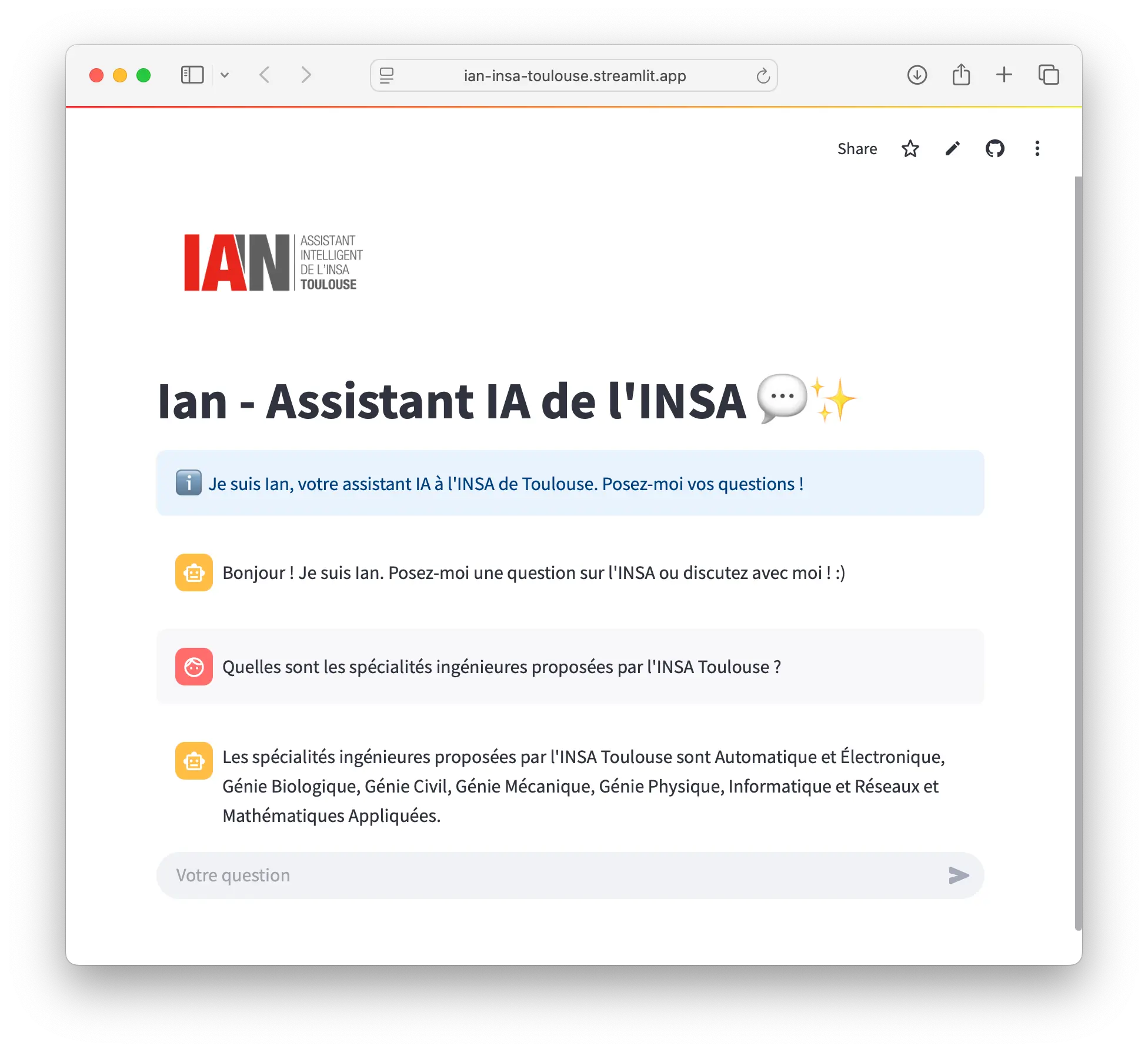
Prototype interface (Streamlit) named IAN. Evaluation on a small question set: 7/8 relevant answers. Additional tooling:
- Cosine similarity diagnostics for chunk usefulness
- Cross‑encoder re‑rankers for precision (MiniLM)
- Binary classifier to detect non‑answerable queries
Results & Impact
RAG significantly outperformed local training and fine‑tuning for the use case. The system provides reliable, updateable guidance for students and administrative queries.
Next Steps
- Index sub‑specializations in FAISS for faster, more accurate retrieval
- Integrate structured sources (schedules, databases) and multimodal inputs
- Deploy monitoring for drift and automated re-indexing